
Bu ay mühendislik kanallarında en çok hangi soruyu aldım?
"Coding agent'larımız için Nemotron 3 Super mı çalıştıralım, Qwen ailesinden bir şey mi?"
Mantıklı soru. İkisi de open-weight, ikisi de kodlama benchmark'larında rekabetçi, ikisi de son aylarda gündemde. Ama cevap göründüğü kadar net değil. İkisi farklı işler için tasarlanmış.
Baktım. İşte tablo.
Sürüm notu: Bu karşılaştırma Nemotron 3 Super 120B-A12B (11 Mart 2026) ile Qwen3-Coder-Next 80B-A3B (3 Şubat 2026) ve karşılaştırılabilir boyuttaki Qwen3.5-122B-A10B'yi kapsıyor. Tüm benchmark verileri Şubat 2026'dan önce yayımlanmayan resmi teknik raporlardan ve bağımsız üçüncü taraf değerlendirmelerinden alındı.
Her Model Ne İçin Optimize Edilmiş?

Nemotron: Agentic iş akışları için
Nemotron 3 Super tek bir iş için inşa edilmiş: çok ajanlı bir kodlama stack'inde planlama ve orkestrasyon beyni olmak. NVIDIA'nın çerçevesi açık — bir pipeline karmaşık görevleri ayrıştırması, tüm codebase context'ini tutması ve işi birden fazla worker agent'a yönlendirmesi gerektiğinde Super burada konumlandırılmış. Genel amaçlı bir konuşma modeli değil, NVIDIA da bunu iddia etmiyor.
NVIDIA teknik raporu (11 Mart 2026) post-training pipeline'ını üç ardışık aşama olarak tanımlıyor: 25 trilyon token üzerinde ön eğitim, agentic görev türleri genelinde SFT ve yazılım mühendisliği, siber güvenlik ve finansal analiz dahil 15 farklı agentic ortamda doğrulanabilir sonuçlara karşı takviye öğrenimi. RL aşaması modelin güçlü çok adımlı akıl yürütmesini ve araç çağrısı sıralamasını üretiyor.
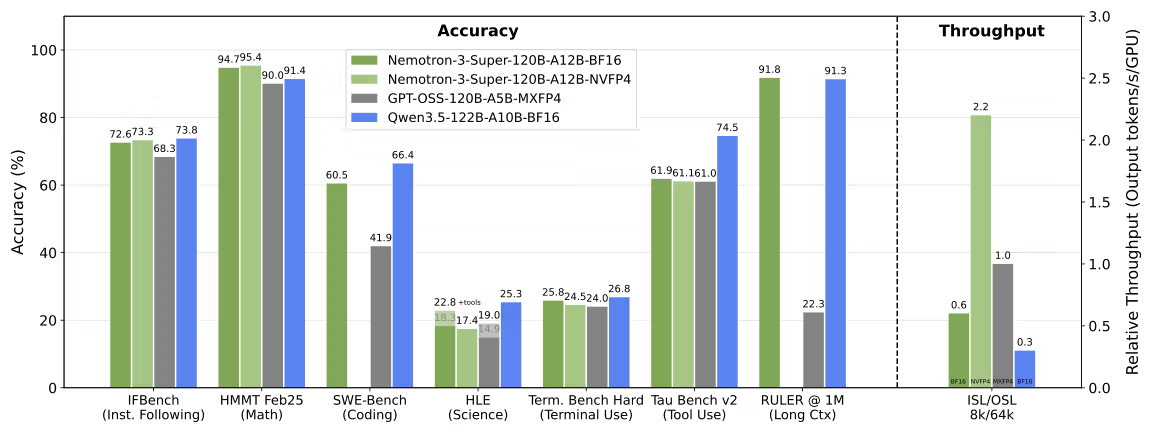
Nemotron 3 Super'ın optimize edilmediği alan: Genel bilgi genişliği ve konuşma kalitesi. Arena-Hard-V2 skoru %73,88 ile GPT-OSS-120B'nin %90,26'sının gerisinde kalıyor; GPQA skoru %79,23 ile Qwen3.5-122B'nin %86,60'ının altında.
Qwen: Genel kodlama gücü için
Qwen ailesi daha geniş bir yaklaşım benimsiyor. Qwen3-Coder-Next, agentic ortamlarda 800.000 doğrulanabilir çalıştırılabilir görev üzerinde eğitildi; uzun vadeli akıl yürütme, araç sıralama, test çalıştırma ve başarısız çalışmalardan kurtarma için takviye öğrenimi uygulandı. Ama Nemotron 3 Super'ın geri çekildiği genel bilgi benchmark'larında da rekabetçi kalıyor — MMLU-Pro'da %86,70 vs. Nemotron'ın %83,73'ü, GPQA'da %86,60 vs. %79,23.
Qwen3-30B-A3B, SWE-Bench Verified'da %69,6 ve ArenaHard'da 91,0 skoru alıyor; hem kodlama hem de konuşma görevlerinde rekabetçi konumlandırılıyor. Daha büyük Qwen3.5-122B-A10B bunu daha da ileriye taşıyor: SWE-Bench Verified'da Nemotron 3 Super'ı geçiyor (%66,40 vs. %60,47) ve bilimsel akıl yürütmede öne çıkarken karşılaştırılabilir bir MoE verimlilik profili koruyor.
Qwen'in optimize edilmediği alan: Aşırı uzunluklarda uzun context tutma. Qwen3.5-122B native olarak 128K context'te sınırlı; Qwen3-Coder-Next 256K desteklese de hiçbiri Nemotron 3 Super'ın 1M token penceresine ulaşmıyor. Retrieval olmadan büyük codebase'lerin tamamını tek context'e yüklemesi gereken pipeline'lar için bu fark önem taşıyor.
Mimari Farklar
Aktif parametre sayısı ve verimlilik
Her iki model de çıkarım maliyetlerini düşük tutmak için Mixture-of-Experts kullanıyor, ama verimlilik oranları anlamlı biçimde farklı:
| Nemotron 3 Super | Qwen3-Coder-Next | Qwen3.5-122B | |
|---|---|---|---|
| Toplam parametre | 120B | 80B | 122B |
| Aktif parametre | 12B (%10) | 3B (%3,75) | 10B (~%8,2) |
| Mimari | Hybrid Mamba-2 + Transformer + LatentMoE | Hybrid GatedDeltaNet + Gated Attention + MoE | Dense Transformer MoE |
| Context penceresi | 1M token (native) | 256K token | 128K token |
| Lisans | NVIDIA Open Model License | Apache 2.0 | Apache 2.0 |
Nemotron 3 Super her forward pass'te 12B parametre aktive ediyor. Qwen3-Coder-Next yalnızca 3B — token başına servis etmesi çok daha ucuz, tüketici donanımında çalışabiliyor (64GB MacBook, RTX 5090) ve mütevazı altyapıda yüksek hacimli eşzamanlı dağıtımlar için daha uygun.
Qwen3-Coder-Next'in ultra-seyrek MoE'su token başına 512 uzmanın 10'unu aktive ediyor; bu da çok daha büyük sistemlerle rekabet eden akıl yürütme yeteneklerini hafif bir yerel modelin düşük dağıtım maliyetleri ve yüksek throughput'uyla birleştiriyor.
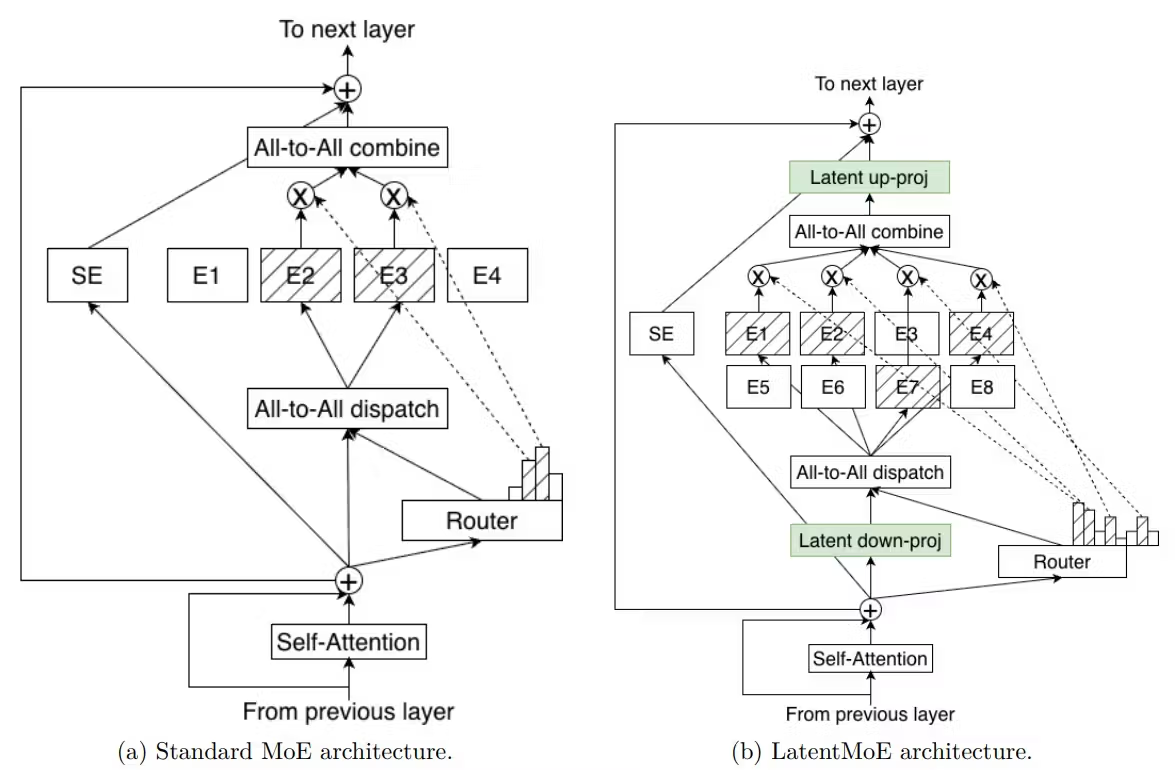
Nemotron 3 Super'ın üç mimari yeniliği farklı katmanlanıyor. LatentMoE, uzman yönlendirmesinden önce token'ları 4096 boyutlu gizli uzaydan 1024'e sıkıştırıyor — aynı hesaplama maliyetiyle daha az uzmanı olan standart bir MoE ile karşılaştırıldığında 22 aktif token ile 512 toplam uzmanı mümkün kılan 4 kat sıkıştırma. Mamba-2 katmanları dizi işlemeyi lineer zaman karmaşıklığıyla yürütüyor. Multi-Token Prediction yerleşik spekülatif kod çözme sağlıyor.
Pratik sonuç: Nemotron 3 Super, ağır context yükleriyle yüksek çıkış token hacminde servis verimliliği için optimize edilmiş. Qwen3-Coder-Next, yüksek frekanslı kısa context iş yüklerinde görev başına maliyet için optimize edilmiş.
Context ve throughput sonuçları
Nemotron 3 Super, 8K giriş / 16K çıkış ayarlarında GPT-OSS-120B'ye kıyasla 2,2 kat, Qwen3.5-122B'ye kıyasla 7,5 kat daha yüksek çıkarım throughput'u elde ediyor. Bu throughput avantajı, birçok agent'ın paralel çalıştığı çok ajanlı orkestrasyon sistemleri için önemli.
1 milyon token'da Nemotron 3 Super, RULER'da %91,75 skoru alırken GPT-OSS-120B %22,30'a düşüyor. Qwen3.5-122B'nin 128K sabit sınırı, tam milyon token erişim görevlerinde rekabet etmesini engelliyor. Qwen3-Coder-Next native olarak 256K'ya makul bir tutmayla ulaşıyor; ama 1M rakamı yalnızca pozisyonel interpolasyon extrapolation ile mevcut — native eğitimle aynı şey değil.
Pratik bir uyarı: Nemotron 3 Super için varsayılan context yapılandırması VRAM kısıtları nedeniyle 256K token; 1M açık bir flag ile erişilebilir. Dolayısıyla çoğu yönetilen API ortamında her iki model de varsayılan olarak 256K'da çalışıyor; 1M avantajı bilinçli altyapı planlaması gerektiriyor.
Kodlama ve Araç Kullanımı Karşılaştırması
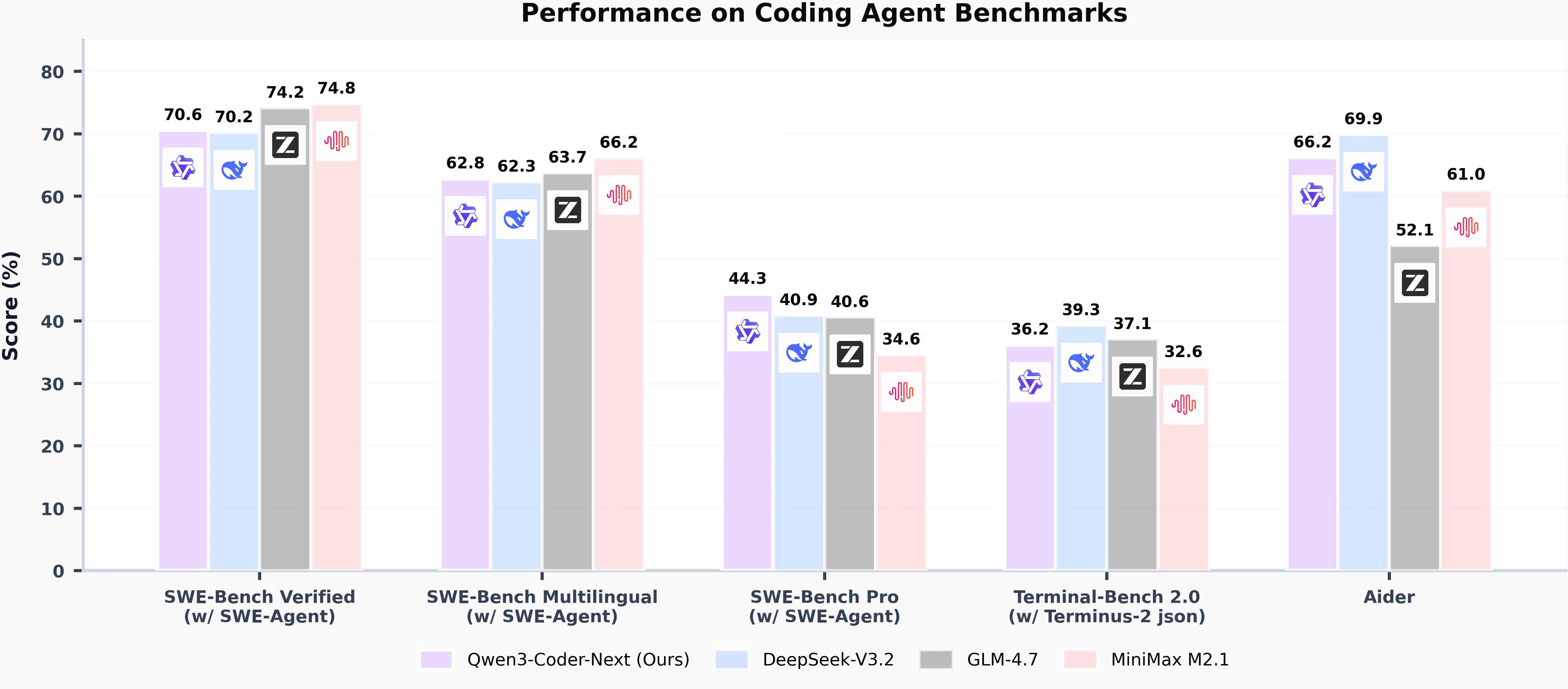
Aşağıdaki tüm skorlar belirtilen scaffold ve tarihleri kullanıyor. Farklı harness'larda çalıştırılan sayıları çapraz karşılaştırma — SWE-Bench Verified skorları kullanılan agent scaffold'a göre önemli ölçüde farklılaşıyor.
SWE-Bench Verified — SWE-Agent scaffold (Mart 2026 verileri)
| Model | SWE-Bench Verified | SWE-Bench Multilingual | SWE-Bench Pro |
|---|---|---|---|
| Qwen3-Coder-Next 80B-A3B | %70,60 | %62,80 | %44,30 |
| Qwen3.5-122B-A10B | %66,40 | — | — |
| Nemotron 3 Super 120B-A12B | %60,47 (OpenHands) | %45,78 | — |
| DeepSeek-V3.2 | %70,20 | %62,30 | %40,90 |
| GLM-4.7 | %74,20 | %63,70 | %40,60 |
Kaynaklar: Qwen3-Coder-Next teknik raporu (Şubat 2026); NVIDIA teknik raporu (Mart 2026). Not: Nemotron rakamları OpenHands harness; Qwen rakamları SWE-Agent scaffold kullanıyor. Doğrudan sayısal karşılaştırma gösterge niteliğinde, kesin değil.
Benchmark harness uyarısı: Nemotron 3 Super'ın %60,47'si OpenHands scaffold kullanıyor. Qwen3-Coder-Next'in %70,6'sı SWE-Agent kullanıyor. Bu iki scaffold aynı modelde sistematik olarak farklı skorlar üretiyor — farklı araç seti, farklı prompting, farklı pass@k stratejisi. Yukarıdaki rakamlar dar anlamda doğrudan karşılaştırılabilir değil. Her iki resmi teknik rapor farklı harness kullandığından modeller arası deltaya uygun şüphecilikle yaklaş.
Şunu söyleyeyim: Nemotron 3 Super'ın SWE-Bench Verified'da %60,47'si Qwen3.5'in yaklaşık 6 puan gerisinde — ama 2,2 kat throughput sunuyor. Çok sayıda agent'ı eşzamanlı çalıştıran sistemler için bu throughput/doğruluk takası önem taşıyor.
LiveCodeBench (bağımsız, Mart 2026)
Güncel, kirletilmemiş kodlama problemlerini test eden bağımsız bir benchmark olan LiveCodeBench'te Nemotron 3 Super %81,19 alıyor; Qwen3.5-122B'nin %78,93'ünün önünde. Bu, Nemotron'ın karşılaştırılabilir parametre bütçe tier'ında Qwen'i geçtiği kategorilerden biri — üstelik eski kodlama değerlendirmelerinden eğitim verisi kirliliğine daha az açık bir benchmark.
Araç çağrısı
Qwen3-Coder-Next araç çağrısı için açıkça ayarlanmış ve Qwen-Code, Claude Code, Cline ile diğer agent arayüzleri gibi IDE ve CLI ortamlarıyla entegre çalışıyor. Thinking modu desteklemiyor (<think> blokları) — yanıtlar görünür akıl yürütme adımları olmadan doğrudan üretiliyor.
Nemotron 3 Super hem reasoning hem de non-reasoning modunu destekliyor. "Araçlarla" GPQA skoru (%82,70), "araçsız" varyantın 3,5 puan üzerinde — araç çağrısı eğitiminin yalnızca görev yürütmeyi değil, temelli akıl yürütmeyi doğrudan iyileştirdiğinin kanıtı.
Her iki model de çok dilli agent iş akışları için gereken 43 programlama dilini karşılıyor. Qwen3-Coder-Next'in SecCodeBench skoru %61,2 (kod güvenlik açığı onarımı), Claude Opus 4.5'in %52,5'ini geçiyor — güvenlik odaklı kod oluşturma stack'inin parçasıysa anlamlı bir fark.
Dağıtım Farkları
NIM vs yaygın open-model yolları
Bu iki modelin anlamlı ölçüde farklı dağıtım ekosistemi var. Production'a giden yolu anlamak, benchmark skorları kadar önemli.
Nemotron 3 Super dağıtım seçenekleri (13 Mart 2026 itibarıyla):
| Yol | Detaylar |
|---|---|
| NVIDIA NIM mikroservis | Paketlenmiş çıkarım container'ı; vLLM, TensorRT-LLM, SGLang destekli |
| build.nvidia.com | Ücretsiz deneme API erişimi |
| Google Cloud Vertex AI, OCI, CoreWeave, Together AI | Yönetilen bulut API'leri |
| Hugging Face | BF16, FP8, NVFP4 checkpoint'leri |
| Self-host | Minimum 8x H100-80GB (BF16); FP8'de 4x H100 uygulanabilir |
NVIDIA NIM paketlemesi enterprise ekipler için gerçek bir avantaj: standartlaştırılmış çıkarım container'ları, SLA destekli bulut dağıtımları ve NVIDIA altyapısı üzerinden on-prem özel dağıtıma net bir yol. Takas: lisans Apache 2.0 değil, NVIDIA Open Model License — ticari kullanım için izin verici, ama NVIDIA'ya karşı dava açarsan patent fesih maddesi içeriyor.
Qwen3-Coder-Next dağıtım seçenekleri (13 Mart 2026 itibarıyla):
| Yol | Detaylar |
|---|---|
| Hugging Face | 4 ağırlık varyantı: BF16, GGUF Q4/Q8, FP8 |
| Together AI | Production API, FP8 varyantı |
| Kaggle | Ücretsiz çıkarımlı model hosting |
| Yerel (Ollama, LMStudio, llama.cpp) | 64GB MacBook, RTX 5090, RX 7900 XTX'te çalışıyor |
| Lisans | Apache 2.0 — tam ticari esneklik |
Qwen3-Coder-Next, yalnızca 3B aktif parametre kullanırken kodlama benchmark'larında Claude Sonnet 4.5 ile karşılaştırılabilir performans sunuyor; bu da yüksek seviyeli tüketici donanımında çalıştırmayı uygulanabilir kılıyor. Güçlü bir coding agent'ı tamamen yerel çalıştırmak isteyen — API maliyeti yok, tam veri kontrolü — bir geliştirici için Qwen3-Coder-Next, Mart 2026 itibarıyla bu tier'daki en uygulanabilir seçenek. Nemotron 3 Super'ı self-host etmek minimum 8x H100-80GB gerektiriyor; bireysel geliştiriciler veya küçük ekipler için anlamlı bir engel.
API fiyat karşılaştırması (Mart 2026, DeepInfra / Together AI spot fiyatları):
| Model | Giriş (1M token başına) | Çıkış (1M token başına) |
|---|---|---|
| Nemotron 3 Super | ~$0,10–$0,30 | ~$0,50–$0,80 |
| Qwen3-Coder-Next | ~$0,06–$0,18 | ~$0,20–$0,50 |
Fiyatlar sağlayıcıya göre değişiyor ve güncellenecek. Bütçelemeden önce sağlayıcı sayfalarını doğrudan kontrol et.
Hangisini Seçmelisin?
Nemotron 3 Super'ı seç, eğer…
Çok ajanlı bir orkestrasyon sistemi kuruyorsan ve bir modelin karmaşık görevleri planlayıp worker agent'lara yönlendirmesi gerekiyorsa — bu modelin tasarım hedefi tam olarak bu.
1M token context gerekiyorsa ve bu context'in gerçekten tuttuğunu görmek istiyorsan — RULER@1M'de %91,75, teknik bir "1M token destekliyor" iddiasından farklı.
NVIDIA Blackwell altyapısında yüksek hacimli eşzamanlı agent iş yükü çalıştırıyorsan ve 2,2 kat+ throughput avantajı servis maliyetini anlamlı ölçüde düşürüyorsa.
Ekibin enterprise dağıtım desteğine ihtiyaç duyuyorsa — NIM paketleme, bulut SLA'ları ve NVIDIA altyapısı üzerinden on-prem özel dağıtım.
Çok dilli kod öncelikli ise: SWE-Bench Multilingual'da %45,78, GPT-OSS-120B'nin %30,80'inin gerçekten önünde — İngilizce dışı codebase'ler için anlamlı bir fark.
Seçme, eğer Apache 2.0 lisans özgürlüğüne, geniş bilimsel akıl yürütme derinliğine, tüketici donanımında dağıtılabilirliğe ya da kodlama yeteneğinin yanında güçlü konuşma kalitesine ihtiyacın varsa.
Qwen 3'ü seç, eğer…
Open-weight sınıfında en yüksek ham SWE-Bench Verified skorunu istiyorsan — Qwen3-Coder-Next %70,6 ile (SWE-Agent) bu tier'da şu an önde.
Tüketici donanımında tamamen yerel çalıştırman gerekiyorsa — 64GB MacBook veya RTX 5090'da Qwen3-Coder-Next teorik değil, gerçek bir dağıtım yolu.
Apache 2.0 lisansı zorunlu şartsa — patent maddesi yok, lisans şartlarının ötesinde atıf zorunluluğu yok, maksimum ticari esneklik.
Yüksek frekanslı kısa context görevleri çalıştırıyorsan ve 3B aktif parametre, ölçekte görev başına maliyeti dramatik biçimde düşürüyorsa.
Güvenlik odaklı kod oluşturma önemliyse: SecCodeBench'te %61,2, bu kategoride daha büyük kapalı modelleri geçiyor.
Kodlamanın yanında genel zeka da gerekiyorsa — bir modelin saf agent orkestrasyon ötesinde birden fazla kullanım senaryosuna hizmet etmesi gereken ekipler için Qwen3.5-122B, MMLU-Pro, GPQA ve ArenaHard'da önde.
Seçme, eğer pipeline'ın doğrulanmış retention ile native 1M token context'e bağımlıysa, NVIDIA NIM enterprise paketlemesine ihtiyacın varsa ya da NVFP4 verimliliğinin belirleyici olduğu Blackwell donanımında yüksek çıkışlı eşzamanlı orkestrasyon çalıştırıyorsan.
Kısacası: bu iki model aynı iş için rekabet etmiyor.
Nemotron 3 Super, enterprise NVIDIA altyapısı üzerinde çalışan çok ajanlı bir sistemin beyni olmak için inşa edilmiş. Qwen3-Coder-Next, güçlü ham benchmark sayıları olan maliyet etkin, yerel dağıtılabilir, Apache lisanslı bir coding agent için tasarlanmış. Doğru seçim neredeyse tamamen dağıtım kısıtlamalarına ve stack mimarisine bağlı — leaderboard'daki hangi sayının daha büyük olduğuna değil.
Hâlâ karar veremiyorsan en hızlı yol her ikisini de gerçek iş yüklerine karşı çalıştırmak. Her ikisi de ücretsiz tier API erişimi sunuyor. Kullan.
İyi kodlamalar.
