
Agent Swarm is not a new concept. Coordinating multiple AI agents toward a shared goal has been a standard pattern in LangGraph, CrewAI, and custom orchestration frameworks for over a year. What K2.6 does differently is absorb that coordination layer into the model itself — making the orchestration a first-party architectural feature rather than infrastructure you build and maintain. Whether that tradeoff is worth it for your use case is what this article addresses.
What Agent Swarm Actually Does

At a mechanical level, Agent Swarm is K2.6's ability to decompose a complex task into heterogeneous subtasks, spawn specialized sub-agents to execute them in parallel, and synthesize their outputs through a shared state coordinator. The official documentation describes K2.6 as "adaptively coordinating tasks based on agent skill profiles" — which is a terse way of saying it decides what kind of work each subtask requires and routes accordingly, rather than cloning itself uniformly across all subtasks.
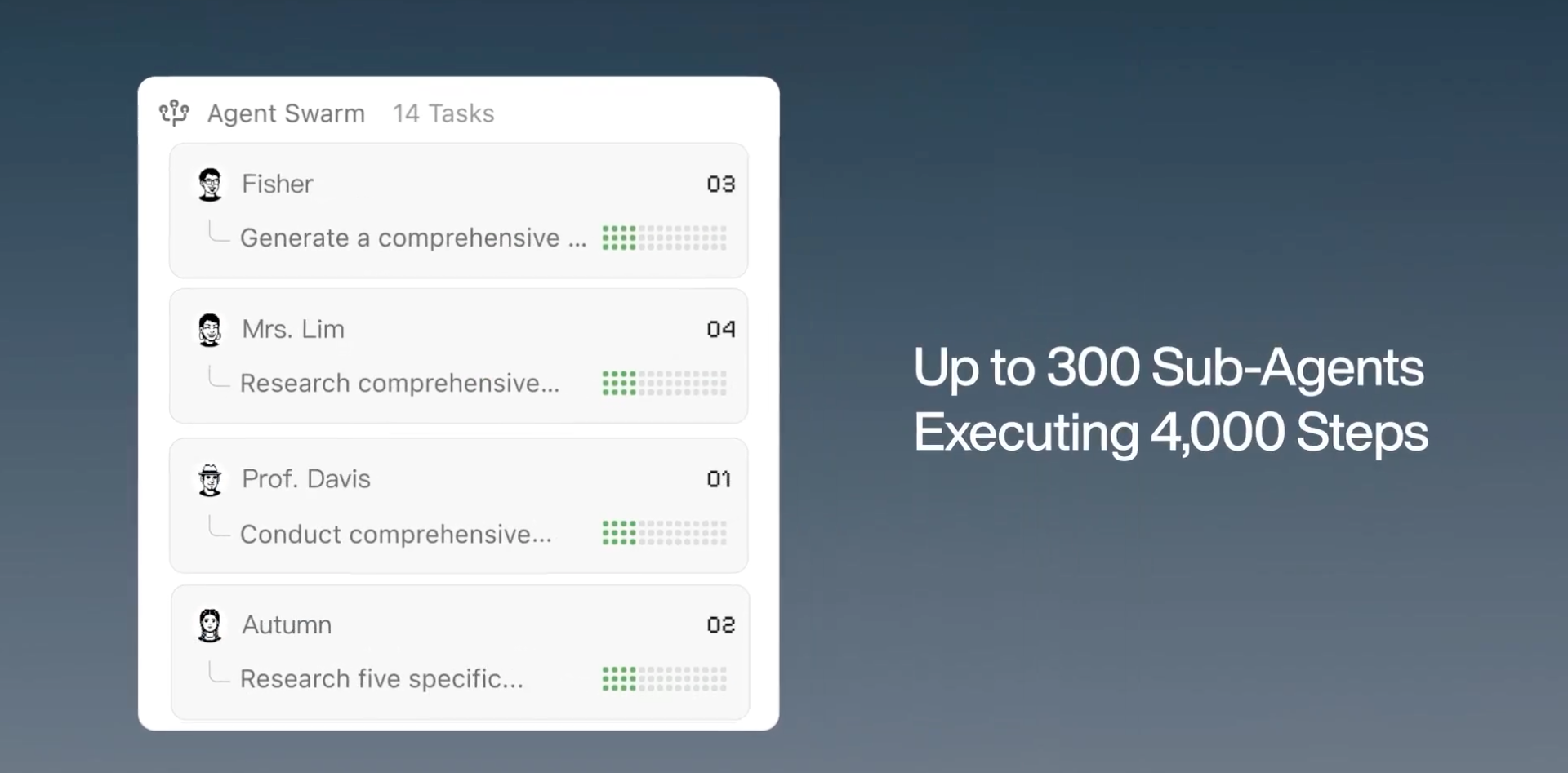
The stated ceiling is 300 parallel sub-agents executing across 4,000 coordinated steps. The 4,000 steps is not a per-agent limit — it's the total coordinated step budget across the swarm, which is meaningfully different. A 300-agent swarm with a 4,000-step budget averages roughly 13 steps per agent, which maps to short, specialized subtasks rather than deep individual runs. Tasks that require deep sequential reasoning by a single agent use that budget differently than tasks that decompose into many shallow parallel subtasks.
The document-to-skill conversion capability added in K2.6 is worth noting separately: PDFs, spreadsheets, slides, and Word documents can be turned into agent skills, meaning sub-agents can carry domain-specific knowledge drawn from uploaded files rather than relying entirely on the base model's training.
How 300 Sub-Agents Are Coordinated
Task decomposition
K2.6 uses heterogeneous decomposition rather than uniform parallelism. When a complex task arrives, the coordinator (K2.6 itself) analyzes the task structure and assigns subtasks based on skill profiles — code refactoring to a code agent, research synthesis to a research agent, documentation generation to a writing agent — rather than distributing identical work across identical agents. The official description frames this as "dynamically matching tasks to agents based on their specific skill profiles and available tools."
In practice, this means the decomposition quality is the first place a swarm can fail. If the coordinator's understanding of what the task requires is wrong — because the initial prompt is ambiguous, or because the task is genuinely novel — the subtask assignments will be wrong from the start, and sub-agents will work efficiently in the wrong direction.
Routing and skill-matching
Sub-agent routing in K2.6 runs through what Moonshot describes as a shared operational space. Agents have persistent memory contexts and available toolkits defined at spawn time; the coordinator tracks skill profiles and routes work accordingly. The Claw Groups feature (currently research preview) extends this further: it allows humans and agents from heterogeneous sources — any model, any device — to participate in the same swarm, with K2.6 coordinating across the mixed pool.
What's not publicly documented: the specific mechanism by which K2.6 determines skill profiles, how it represents agent state internally, and how the shared state handles conflicts when multiple agents attempt to modify the same resource. These are real engineering questions for anyone evaluating whether to build on this infrastructure versus implementing their own orchestration with explicit state management.
Failure recovery
The official model card states that K2.6 "detects when an agent encounters failure or stalls, automatically reassigns the task or regenerates subtasks." The mechanism behind this detection is not publicly specified. From the outside, the behavior is: stalled sub-agents are identified by the coordinator, their tasks are re-queued or split into smaller units, and execution continues. What triggers the stall detection — timeout, error signal, output validation failure, something else — is opaque.
This opacity matters for production use. With external orchestration frameworks like LangGraph, you define stall detection yourself: a timeout, a retry limit, a health check. You control the arbitration. With K2.6's in-model swarm, the recovery happens automatically, which is convenient, but the recovery logic cannot be inspected or tuned. If K2.6's stall detection is miscalibrated for your task type — triggering too early or too late — you cannot adjust it.
The Jump from K2.5 (100 Agents, 1,500 Steps) to K2.6 (300 Agents, 4,000 Steps)
| Capability | K2.5 | K2.6 | Change |
|---|---|---|---|
| Max parallel sub-agents | 100 | 300 | 3× |
| Max coordinated steps | 1,500 | 4,000 | 2.7× |
| Video input | No | Yes | Added |
| Claw Groups (heterogeneous swarms) | No | Research preview | Added |
| BrowseComp (Agent Swarm mode) | 78.4 | 86.3 | +7.9 points |
The architecture is unchanged between K2.5 and K2.6. Moonshot's deployment guide explicitly states the two models share the same architecture and deployment method. The delta is posttraining: more training compute applied to long-horizon stability, instruction following, and swarm coordination. Moonshot has not disclosed the specific training changes.
The BrowseComp improvement in Agent Swarm mode (+7.9 points) is the only publicly reported benchmark that isolates the swarm architecture specifically. Both numbers are from Moonshot's own model card, not third-party evaluation.
Real Execution Cases Worth Trusting
These three cases are Moonshot's own internally-run demonstrations. They are sourced from the official Kimi K2.6 technical blog. They are vendor-reported results, not independently verified by third parties. As DEV Community noted in their K2.6 analysis: no complete public patch set, raw flame graphs, or full execution logs exist for the exchange-core rewrite at the time of this writing. VentureBeat's reporting separately quotes practitioner Maxim Saplin: "orchestration is still fragile... it feels more like a product and training problem than something you can solve by writing a sufficiently stern prompt." Read them as upper-bound capability signals, not guaranteed outcomes.

13-hour exchange-core refactor
K2.6 was given exchange-core, an eight-year-old open-source Java financial matching engine. The run lasted 13 hours, involved 12 distinct optimization strategies, over 1,000 tool calls, and modifications to more than 4,000 lines of code. The model analyzed CPU and memory flame graphs, identified hidden bottlenecks, and reconfigured the core thread topology — changing from a 4ME+2RE to a 2ME+1RE configuration. The reported result: medium throughput improved from 0.43 MT/s to 1.24 MT/s, a 185% gain. Peak throughput improved 133%.
The engineering task is credible. Reading an unfamiliar Java codebase, profiling at the flame graph level, and rewriting thread topology without breaking matching invariants is the kind of work that takes a competent systems engineer days. What cannot be verified externally: whether correctness was preserved across all edge cases, what the failure/retry rate was across the 12 strategies, and how much of the result generalizes to similar codebases versus being specific to exchange-core's structure.
12-hour Zig optimization of Qwen3.5 inference
K2.6 was tasked with downloading and locally deploying Qwen3.5-0.8B on a Mac, implementing inference in Zig, and optimizing throughput. Zig is a niche systems language with a small training corpus; the model had to generalize across a domain it has limited direct training data for. The run lasted over 12 hours, involved 4,000+ tool calls across 14 iterations, and improved throughput from approximately 15 to 193 tokens per second — roughly 20% faster than LM Studio on the same hardware.
The Zig detail is the interesting part. Most models improve throughput in Python or Rust, which have substantial training data. Zig suggests out-of-distribution generalization in systems programming, which is harder to fake. The 20% LM Studio comparison is Moonshot's own measurement under unspecified hardware and configuration conditions.
5-day autonomous infrastructure agent
Moonshot's own RL infrastructure team deployed a K2.6-backed agent that operated autonomously for five consecutive days, handling monitoring, incident response, and system operations. This is an internal use case with no external validation. The significance is architectural: it demonstrates that the context management and failure recovery mechanisms function well enough for sustained production-like operation, at least in Moonshot's own infrastructure environment.
Five days is qualitatively different from 12 or 13 hours. It implies the agent was handling novel incidents that weren't in its original task scope — not just executing a predefined plan. What's not documented: how many times human intervention was actually needed despite the "autonomous" framing, and what the failure modes were when they occurred.
Where Swarm Orchestration Still Breaks

State drift
Over long runs, sub-agents can develop inconsistent views of shared state. Agent A modifies a data structure; Agent B operates on a stale snapshot. K2.6's shared operational space is designed to prevent this, but Moonshot has not published the specific consistency model it uses. For coding tasks where multiple agents are modifying the same codebase concurrently, the risk is that integration produces a working component that breaks invariants established by another agent working in parallel.
This is the same problem git merge handles for humans — and git solves it with explicit conflict detection and human resolution. Agent Swarm's automatic conflict resolution is convenient, but the resolution logic is not auditable.
Coordinator bottlenecks
When the coordinator's capacity is saturated — either by the volume of sub-agent status updates or by the complexity of re-planning when subtasks fail — the entire swarm slows. The coordinator is not a separate system; it's K2.6 itself wearing a coordination hat. A coordinator that's busy re-planning a stalled subtask may deprioritize other sub-agents' results, introducing queuing latency that compounds across a 300-agent swarm.
For tasks decomposable into genuinely independent subtasks with minimal coordination overhead, this is manageable. For tasks with high inter-agent dependencies — where Agent B cannot proceed until Agent A produces a specific output — coordinator bottlenecks can serialize what should have been parallel work.
Cost explosions
A 300-agent swarm with K2.6's token economics can burn through budget quickly. The math: 300 agents × even a modest 8,000 output tokens each = 2.4 million output tokens per run. At K2.6's API pricing of approximately $3/M output tokens (actual rate varies by provider; verify before budgeting), that's $7.20 per swarm execution. For a task that requires multiple swarm iterations, costs can exceed $50–100 per task. The Moonshot API also has per-account concurrency limits — production setups typically run 50–100 concurrent requests with queuing for the remainder.
Automatic caching of shared system prompts reduces input costs by 75–83% for subsequent agents in a run, which partially offsets the volume. But output token costs don't benefit from caching. Budget the output tokens first.
How This Maps to Multi-Agent Development Workflows in Production
Agent Swarm represents a specific architectural choice in a space where there are meaningful alternatives. Understanding the tradeoff is more useful than treating it as universally superior.
K2.6 Agent Swarm is model-native orchestration. The coordination, routing, and failure recovery all happen server-side. You make one API call; you get one synthesized output. The overhead of building orchestration infrastructure is zero. The overhead of auditing or customizing orchestration is also zero — because you can't.
LangGraph-style orchestration gives you full control over the graph structure, state transitions, retry logic, and arbitration. You define the roles, the handoffs, the failure conditions. The output is fully auditable; every agent turn is logged and inspectable. The cost is engineering effort to build and maintain the orchestration layer. For teams with existing orchestration infrastructure, this is often the right choice — the control it provides is exactly what makes production debugging tractable.
Parallel worktree platforms — tools like Verdent's multi-agent mode or oh-my-codex's omx team command — sit closer to the LangGraph end of the control spectrum: they give you configurable agent coordination with git-level isolation for concurrent codebase work. The separation of concerns is explicit: each agent works in its own branch; integration is auditable through standard git history.
The choice isn't about which approach is better in the abstract. It's about where you want the control boundary. Agent Swarm trades control for zero-infrastructure parallel execution. External orchestration trades setup cost for auditability. Teams that need to explain their agent decisions — to auditors, to security reviewers, to colleagues debugging a failed run — will find external orchestration's transparency worth the setup cost.
FAQ
Can I use Agent Swarm outside Kimi.com?
Yes. The grok-4.20-multi-agent-0309 API equivalent for K2.6 is the standard Moonshot API endpoint at platform.moonshot.ai. The multi-agent architecture is exposed through an OpenAI-compatible interface. You define a task; K2.6 handles the decomposition, routing, and synthesis server-side. You see the final output, not the internal swarm state.
For maximum parallelism, the practical API guidance is 50–100 concurrent requests with semaphore-based queuing for the remainder. The model card and deploy documentation are on the official Hugging Face model card.
Does every sub-agent run K2.6?
In Moonshot's hosted swarm infrastructure, yes. Claw Groups (research preview) changes this: it allows heterogeneous agents — running other models, running locally, running on mobile — to participate in the same swarm alongside K2.6 sub-agents. In that configuration, K2.6 acts as the coordinator and skill-matcher, but the actual execution may happen on other models or custom agents with their own toolkits.
What happens when the coordinator fails?
This is not publicly documented. Moonshot's model card states that K2.6 "detects when an agent encounters failure or stalls, automatically reassigns the task or regenerates subtasks." What's documented is sub-agent failure recovery. What happens when the coordinator itself encounters an error — context overflow, API timeout, unrecoverable planning failure — is not specified. For production workloads, this is a material unknown. Until Moonshot publishes specifics or the community develops empirical data from long-horizon runs, the appropriate posture is to build external checkpointing for runs longer than a few hours.
How is this different from LangGraph-style orchestration?
LangGraph (v1.1.8, Python ≥3.10) gives you a typed state graph where every node, every edge condition, and every retry policy is code you write and control. You can inspect every agent turn, interrupt at any node, log the full trace, and tune the graph structure based on what you learn from failures. K2.6's Agent Swarm is a black box by comparison: the decomposition, routing, and arbitration all happen inside Moonshot's infrastructure. You get the output but not the process. LangGraph is better for auditable, maintainable orchestration. K2.6 Agent Swarm is better for getting parallel agent execution without writing the orchestration layer yourself. They're optimized for different constraints.
Bottom Line
Agent Swarm's 300-agent, 4,000-step ceiling is a real architectural advance over K2.5, and the exchange-core and Zig demonstrations show genuine capability at the frontier of long-horizon autonomous coding. Both of those facts coexist with the following: all three "real execution cases" are Moonshot's own internal demonstrations without independent verification, the coordinator failure mode is undocumented, and the control tradeoffs are real for any team that needs to audit, customize, or debug their agent execution.
The architecture is worth evaluating for tasks that decompose cleanly into parallel subtasks and where autonomous orchestration is preferred over DIY. It is not the right choice for teams that need to explain their agent decisions, tune their orchestration logic, or maintain strict cost control across variable-complexity swarm runs.
Related Reading
- What Is Kimi K2.6? Moonshot AI's Open-Weight Agent Model Explained
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
- Grok 4.20 Multi-Agent System: How the 4 Agents Work
