
SWE‑bench is a widely adopted benchmark for evaluating coding agents on real-world software engineering tasks. SWE-bench consists of 2,294 real GitHub issues pulled from popular open-source repositories. For each task, the coding agent is given a docker environment and the checkout of codebase from just before the issue was resolved. The agent then needs to understand, modify, and test the code according to the issue description, and submit its solution to be graded against the real unit tests from the pull request that closed the original GitHub issue.
SWE-bench measures not just the model in isolation, but rather the entire agent system. The agent scaffolding around the model — including prompts, tools given to the model, parsing of model's output to take action, management of memory, and engineering of context — plays a crucial role in an agent's performance on SWE-bench, even when the underlying model remains the same.
SWE-bench Verified is a human-validated 500 problem subset of SWE-bench, since the original SWE-bench contains some tasks that are impossible to solve without additional context. SWE-bench Verified has been rigorously reviewed by experienced human developers to ensure solvability, and thus provides reliable measure of coding agents' performance. This establishes SWE-bench Verified as the go-to benchmark for coding agents.
We evaluated Verdent on SWE-bench Verified and found that it resolved 76.1% of issues on the first attempt (pass@1) and 81.2% within three attempts (pass@3). Notably, Verdent delivers this state-of-the-art performance on challenging, real-world coding tasks right out of the box — with no leaderboard tuning or test-time scaling (such as generating multiple candidates and then selecting one). These results come from the same production-grade agent that our users can directly access.

What is Verdent?
Verdent is our state-of-the-art coding agent system that unites multiple agents and subagents within a cohesive workflow to amplify the engineering brilliance of human developers. By coordinating parallel agents powered by top-tier AI models, Verdent excels at executing the plan-code-verify development cycle. Designed for seamless integration, Verdent connects directly to the original Visual Studio Code as an extension and is also available as a standalone desktop application to unlock its full potential.
Most excitingly for us, Verdent's strong results on SWE-bench Verified come without hacks or benchmark-specific tuning, which can directly translate to real-world, day-to-day software development for our users. We're also building internal benchmarks that consist of real tasks from our own development workflow. Evaluating on these benchmarks helps us continually improve Verdent's agentic coding capabilities and keep track of latest released proprietary and open-source models.
Evaluations and Insights
Performance Metrics
The primary metric on SWE-bench Verified is the resolved rate — the proportion of issues for which a proposed patch successfully fixes the problem. We report performance in both pass@1 (resolved rate within a single attempt) and pass@3 (resolved rate within up to three attempts).
Here's why: pass@1 approximates the agent's expected single-shot performance, which directly correlates to the real user experience when the coding agent is only given a single chance to complete user-specific tasks; pass@3 provides an estimate of attainable performance within a small, practical retry budget, which is motivated by common "vibe coding" workflows where developers frequently explore solutions and experiment through iterative trials and rollbacks. To align with realistic use cases, we compute pass@3 score as the resolution rate when the agent is allowed up to three consecutive attempts on the same issue; an instance is counted as resolved if any of those attempts succeeds. Together, pass@1 captures the baseline performance, while pass@3 quantifies the marginal gains achievable through practical budget of retries.
Variations from Model Provider
Verdent leverages model APIs from multiple providers. In our evaluations, even for the same model (e.g., Claude Sonnet 4.5), some providers deliver consistent performance across runs, while others (e.g., Amazon Bedrock) exhibit noticeably higher variance. Under identical agent scaffold and evaluation setup, the cross-provider gap in pass@1 is as high as 1.2%, as illustrated in the figure below.

Figure 2. Cross-provider model performance variation of Claude Sonnet 4.5 in pass@1 and pass@3 on SWE-bench Verified.
Verdent puts user experience first by choosing providers that deliver both top performance and steady reliability. We are continuously monitoring model behavior on real workloads, so that our users always get dependable, high-performing models — without any intentional regressions or downgrades.
Thinking Matters
Frontier AI models, including Claude Sonnet 4.5, GPT-5, and Gemini 2.5 Pro, can optionally use an internal "thinking process" to improve their reasoning capabilities. Thinking modes are especially effective for complex multi-step tasks such as coding and maths.
We evaluated Verdent + Claude Sonnet 4.5 and Claude Code + Claude Sonnet 4.5 on a randomly selected subset of 100 problems from SWE-bench Verified, comparing performance with and without Thinking. As shown in the table below, the with-Thinking variants consistently outperform their without-Thinking counterparts, highlighting the effectiveness of the model's Thinking mode.
| Verdent + Claude Sonnet 4.5 | Claude Code + Claude Sonnet 4.5 | |
|---|---|---|
| Pass@1 w/o Thinking | 80% | 76% |
| Pass@1 w/ Thinking | 82% | 78% |
| Pass@3 w/o Thinking | 86% | 85% |
| Pass@3 w/ Thinking | 88% | 86% |
Impact of Agent Tools
Real-world software development relies on a broad toolkit — from bash and git to file editors, linters, browsers, and many others. Our internal tests and early user feedback indicate that agents need thoughtfully designed tools. With our curated set of agent tools, Verdent shows clear improvements in real engineering tasks. Yet on SWE-bench Verified, we find that the benchmark is not particularly sensitive to agent toolkit design: powerful and highly-engineered toolsets do not necessarily translate into higher benchmark scores.
We ran an ablation study where we simplified the agent toolkit and removed all the advanced tools. Specifically, we evaluated Verdent (with Claude Sonnet 4.5) using only basic bash, read, write, and edit tools. Surprisingly, performance on SWE-bench Verified changed very little. This suggests a potential bias in current public benchmarks, as the minimal toolset required to succeed on these benchmarks stands in stark contrast to the complexity of real-world software engineering.
Code Review Subagent
For any AI coding tool, it is essential to avoid "AI slop" and ensure that generated code is genuinely production-ready. Verdent introduces multiple quality gates throughout the code generation workflow, most notably a dedicated code-review subagent. This gives our users a powerful mechanism to uphold code quality, surface potential issues and build confidence in AI-generated changes.
In our SWE-bench Verified evaluations, enabling the review subagent yields a measurable gain (approximately 0.5% in pass@3). We believe this modest gain on benchmark score understates the significance of code-review subagent: in real-world software projects, the ability to catch subtle bugs, regressions, or maintainability issues before they land in the codebase has an outsized impact on reliability and developer trust, and long-term project health. Verdent's philosophy is straightforward: AI-generated code should be rigorously reviewed, high-quality, explainable, and ready to ship.
How Does Verdent get 76.1% on SWE-bench Verified?
Seamless Multi-Model Compatibility
Top-tier models are increasingly diverging in specialization: GPT-5 excels at code review and refactoring, while Claude Sonnet 4.5 shines in coding and tool use. As a result, AI coding users often need to switch between frontier models depending on the task. Verdent is designed to operate seamlessly across frontier models. On SWE-bench Verified, we evaluate Claude Sonnet 4.5 and GPT-5 within our Verdent agent, and find that Verdent delivers superior performance on both models, outperforming even their native agent scaffolds (Claude Code and Codex).
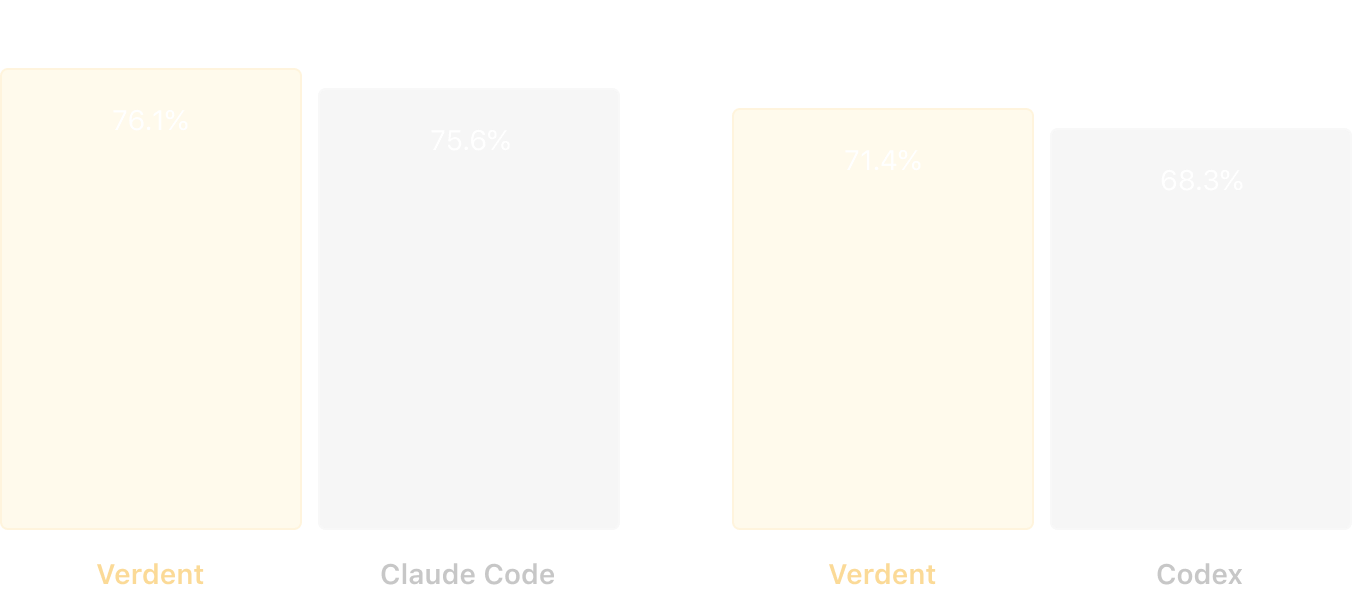
Figure 3. On SWE-bench Verified, Verdent surpasses Claude Code (both paired with Claude Sonnet 4.5), and outperforms Codex (both paired with GPT-5).
Verdent gives developers complete flexibility with seamless, one-click model switching within the same conversation. For example, a user might start with GPT-5 for planning, switch to Claude Sonnet 4.5 for implementation, and then move to GPT-5-Codex for code review and debugging. This transparent, flexible model selection lets our users combine the strengths of multiple frontier models while staying in full control of their development workflow.
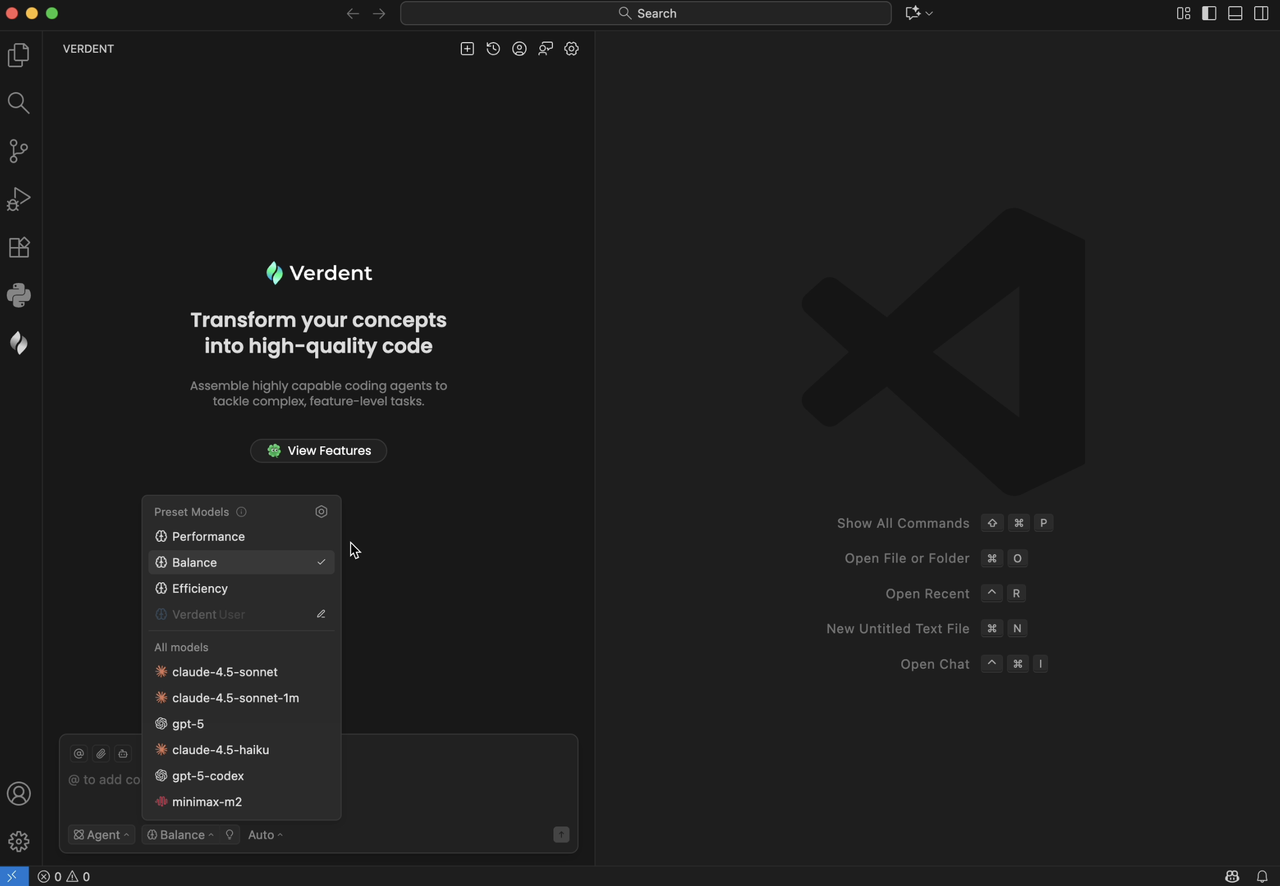
Figure 4. Model selector in Verdent.
Staying on Track with Todos
In day-to-day working, developers often rely on todo lists — mental or written — to structure their workflow. When tackling an issue, they break it into concrete steps: reproducing the bug, pinpointing the root cause, updating the codebase, running tests, and submitting the pull request. Completed steps are checked off, and new ones are added as fresh issues surface. This systematic procedure keeps them oriented in the face of complexity.
Inspired by this human best practice, Verdent maintains an explicit, structured todo list throughout task execution. It continuously reads and updates this todo list as it works, helping both our users and the agent itself track progress on the current task and stay aligned with the latest state. When evaluating on SWE-bench Verified, we find that vague issue descriptions can cause coding agents to lose focus or fall into repetitive, unproductive loops. By anchoring decisions to a clear todo list, Verdent improves task resolution rates while reducing wasted tokens. This design effectively prevents "model drift" and keep the agent focused not only on SWE-bench Verified benchmark problems but also on real-world, complex software engineering tasks.
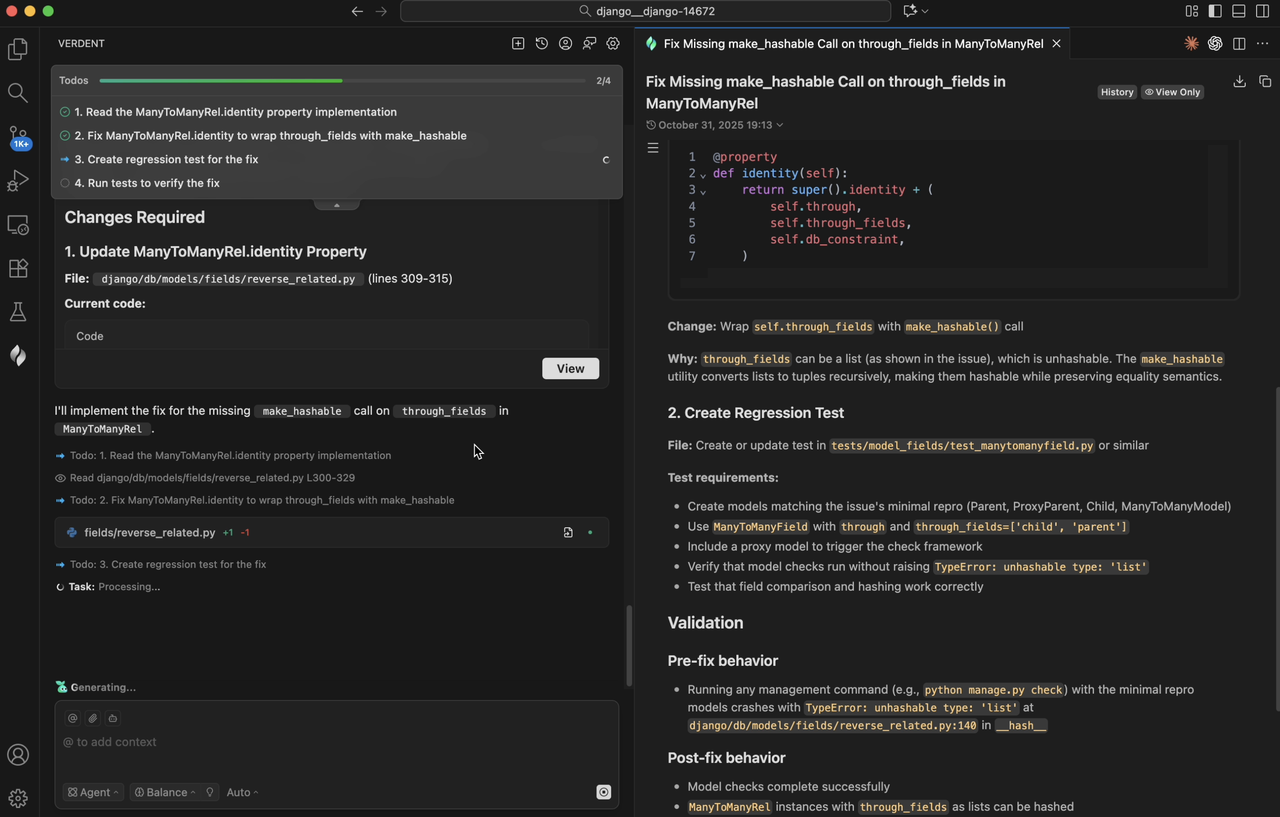
Figure 5. Todo list and progress bar in Verdent.
Verification in the Loop
Verdent treats verification as a first-class stage in the loop, not an afterthought. After meaningful edits, Verdent runs type checks, performs static analysis, and executes tests as needed. For larger changes, Verdent spins up an intelligent code review subagent that inspects the code diff, flags potential risks, and reports back to the main agent once the review is complete. If any regressions are detected, Verdent can automatically trigger a new cycle of debugging and repair.
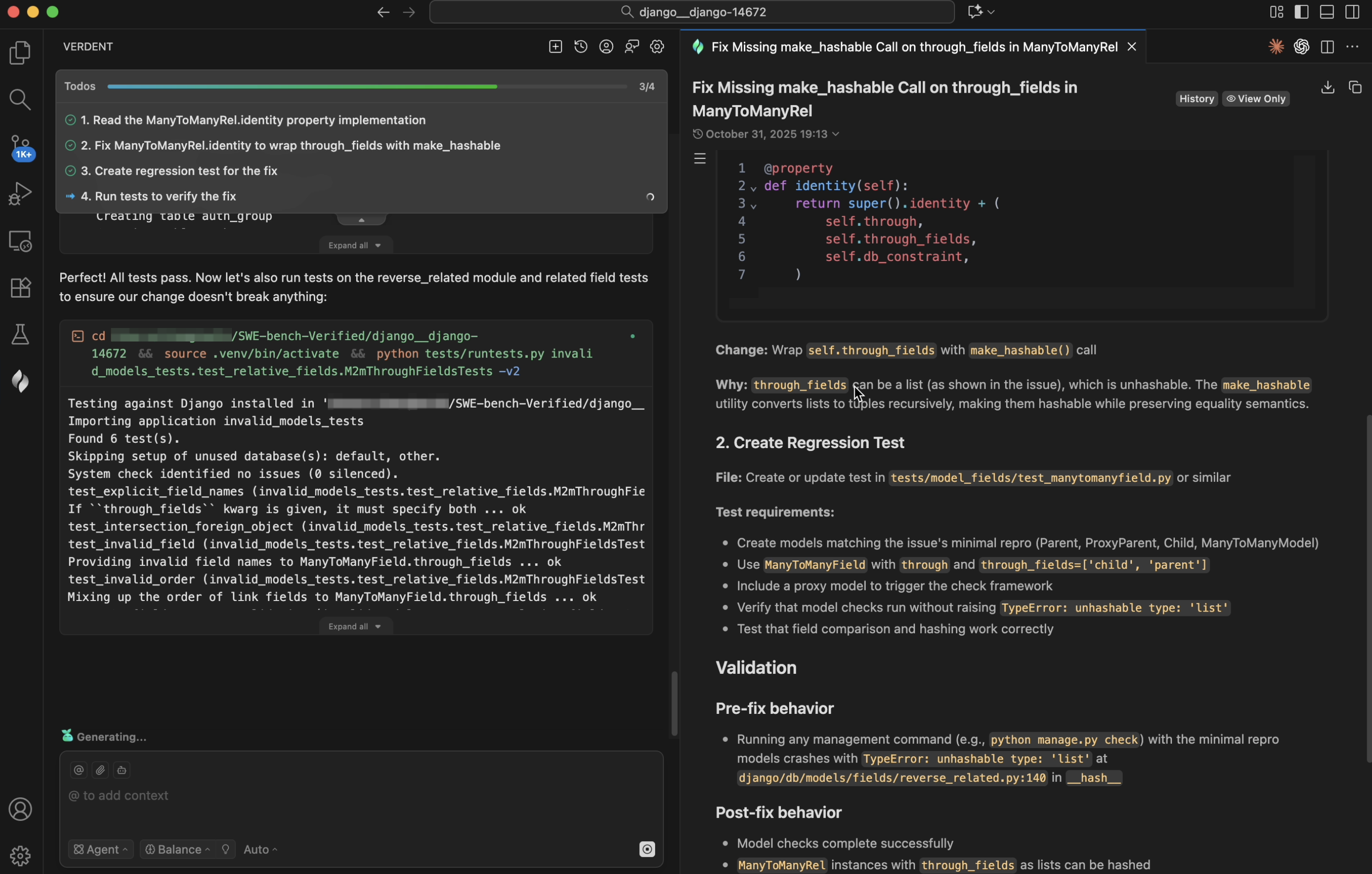
Figure 6. Automatic testing executed by Verdent.
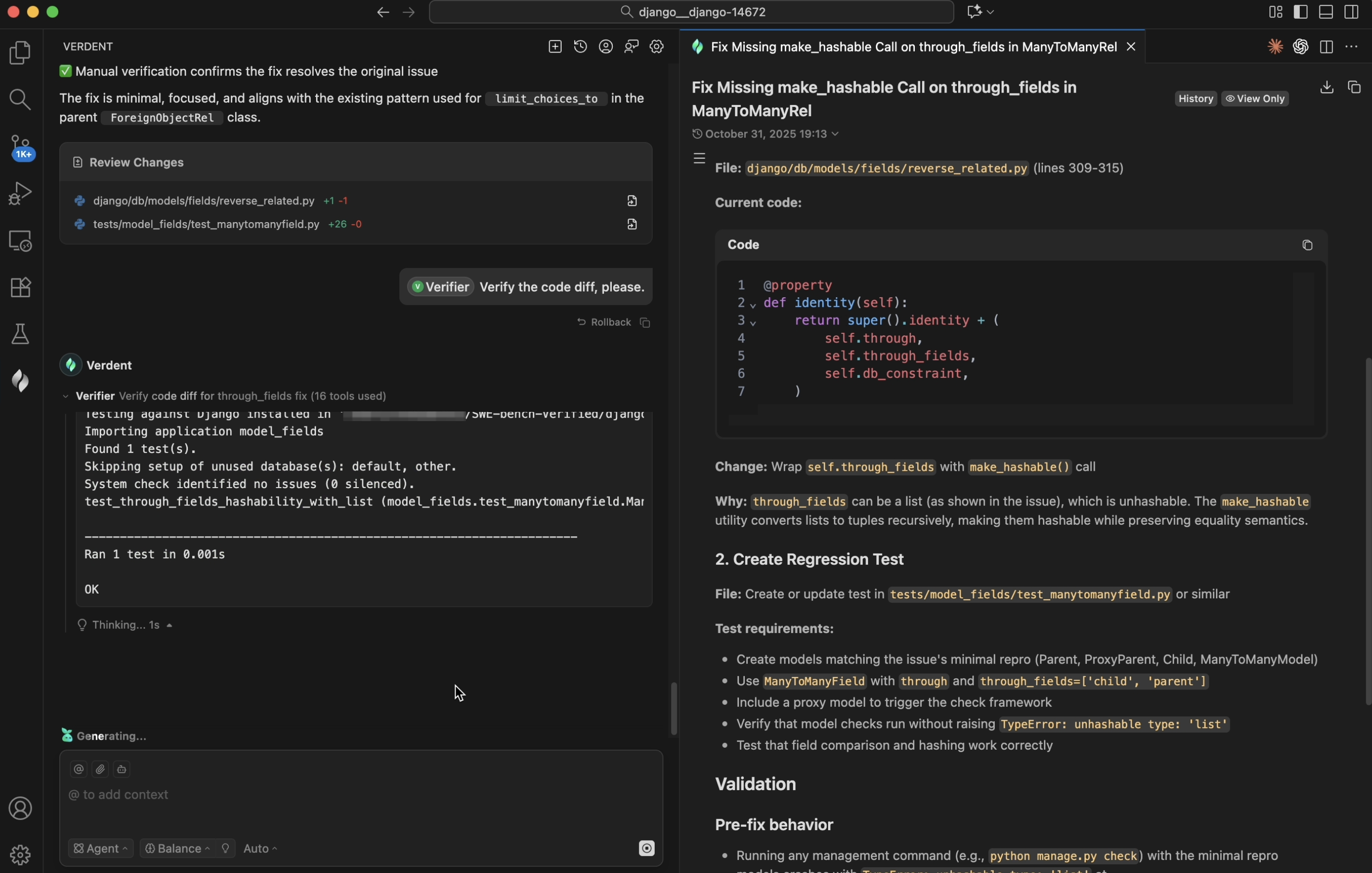
Figure 7. Code verifier subagent in Verdent.